The following site explain every well.
Spark Execution Engine - Logical Plan to Physical Plan










Spark Execution Engine - Logical Plan to Physical Plan
magine a stocks dataset, which has row by row stocks related information – stock symbol, date, opening price, closing price, volume etc for several stocks symbol in text format. Here we see a logical plan for calculating the max volume by stock symbol. First we read the dataset, next we apply the map function to get individual columns (splits RDD). Next we apply another map function to get just symbol and volume column (symvol RDD). Finally we use reducebyKey function to get the maximum volume by symbol (maxvol RDD)

How do you think this logical plan will be converted in to tasks for execution? A task is nothing but a piece of execution. Put yourself in the shoes of spark creators and now take a look at the logical plan. How would you break up this plan in to tasks? How many task do you think you would need to execute this plan?
Strategy 1 – Turn each arrow in to a task
We could consider each arrow that we see in the plan as a task. So we will have 4 tasks between blocks and stocks RDD, 4 tasks between stocks and splits and 4 tasks between splits and symvol.

In that case task 5 for instance, will work on partition 1 from stocks RDD and apply split function on all the elements to form partition 1 in splits RDD. Task 10 for instance will work on all elements of partition 2 of splits RDD and fetch just the symbol and volume to form partition 2 of symvol RDD.
Shuffle in this case could get really messy with this strategy; as we have each partition in maxvol RDD depend on multiple partitions in symvol RDD. So we will end up with lot of tasks.
Problems With Strategy 1
The most obvious problem with this strategy is the number of tasks. Even if we don’t consider the number of tasks we need to execute the shuffle we will need 12 tasks. That’s just too many tasks to manage.
Not only that, each task would generate intermediate data and we need to store and keep track of all the intermediate data some how. So this strategy has memory or storage challenges.

Also, this strategy will also take a heavy hit on performance. Because for instance, to create partition 1 in splits RDD we have to loop through all the elements in partition 1 in stocks RDD and then again to create partition 1 in symvol RDD we have to loop through again all the elements in partition 1 in splits RDD. It just seems redundant doesn’t it?
Clearly this strategy is not efficient in terms of memory or storage utilization and not also efficient when it comes to performance. So lets just scrap this strategy.
Could you think of any other strategy? The problem with the strategy we just discussed is that there are just too many tasks. So let’s think of an strategy where we have less number of tasks.
Strategy 2 – Each Partition is Assigned a Task
We know we have 4 partitions in the final RDD that is maxvol. So what if we have 4 tasks. Task 1 will take care of all executions to create partition 1 in maxvol RDD that is from stocks RDD all the way to the maxvol RDD – Follow the black arrows to track task 1. Similarly task 2 will take care of all executions to create partition 2 in maxvol RDD.

At run time these 4 tasks could be executed in parallel. Task 1 will be executed on node 1, task 2 on node 2 etc. Compared to our previous strategy. We went from 12 tasks to 4 tasks. That is good. Since we have less number of tasks we don’t have lot of intermediate data.
Problems with Strategy 2
We went from one extreme to another. That is, we went from many tasks to very few tasks. The problem with this strategy is, each task will now have more to do and this might be OK for a small logical plan like the one we see here but certainly be a problem for complex bigger plans.

We know that the dependency between symvol RDD and maxvol RDD is a wide dependency. Meaning each partition in maxvol RDD has multiple parent partitions in symvol RDD and each partition in maxvol depend on a portion of its parent partitions in symvol.
For instance, at runtime lets say partition 1 in maxvol is assigned to deal with records for symbol Apple. Let say we have records for Apple in all 4 partitions of symvol RDD. So this means we need to copy apple records from partition 2, 3 and 4 which reside in node 2, 3 and 4 to partition 1 in maxvol which resides in node 1. What we are talking about here is a classic shuffle operation. This is very important. Wide dependency always result in a shuffle operation. Whenever you see a wide dependency you are looking at a shuffle operation.
Let’s talk about Hadoop MapReduce implementation for a second. Hadoop MapReduce implementation has 3 phases. Map, shuffle and reduce phases. Mappers do their thing in Map phase. Reducers do their thing in reduce phase and shuffle phase is when the data need for the reducer gets transferred from mappers to reducers. There are clear segregation of duties in each phase which makes the design simple. When you have a simple design, the technical implementation is also very simple.
Let’s look at our design here. Task 1 is executed on node 1 and task 1 is doing end to end execution including the shuffle there is no segregation of duties. Same is true for other tasks 2,3 and 4 as well. If we go by this strategy, the design is not as simple and elegant as Hadoop’s MapReduce implementation. When the design is not simple, the technical implementation will also be not simple.
Here are the problems with this strategy, very few tasks and our design is not simple which will lead to complicated technical design.
The Solution
So this is what the spark creators did, whenever a wide dependency was encountered in the plan, they broke the execution chain. So wide dependency will become the task execution boundary.
In our plan we have wide dependency between symvol and maxvol RDD. So we will divide the execution in to two parts and spark refers to the parts as stages. For this logical plan, we will end up with 2 stages – stage 0 and stage 1. Now let’s draw out the tasks involved in each stage.
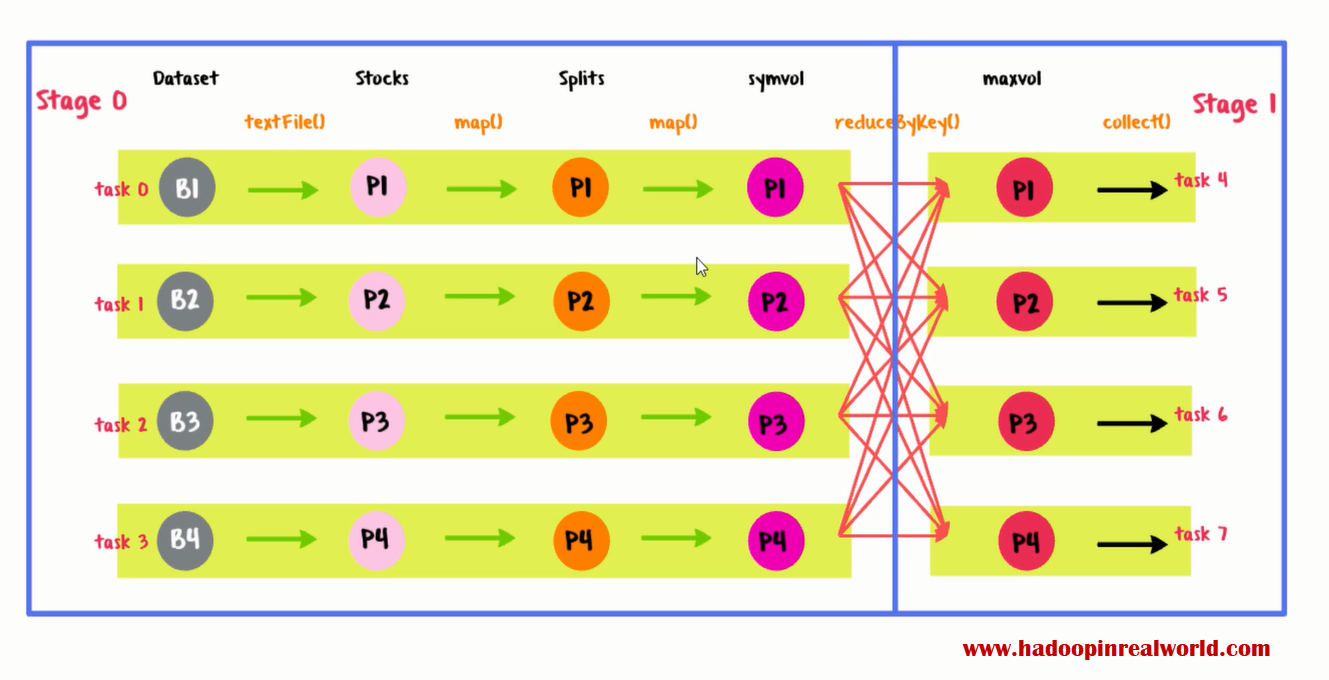
Let’s start with stage 0. To get partition 1 in symvol, we need to compute partition 1 in splits, to compute partition 1 in splits we need partition 1 in stocks. If you think about it, we have combined all the narrow dependencies together. Spark uses zero based index so the first task will be task 0. We will have 4 tasks in stage 0 – task 0, 1, 2 and 3. Let’s move on to stage 1. We have only one RDD in stage 1 and 4 partitions in the RDD. We will have task 4, 5, 6 and 7. So 4 tasks in stage 0 and 4 tasks in stage 1. A total of 8 tasks.
We don’t have too many or too little tasks. We have the right number of tasks this time. Also we have used wide dependency as our task execution boundary which has simplified the design which means the technical implementation will also be simple. If you haven’t realized already, dependencies play a major role in planning out the execution. wide dependencies are used to create stages and narrow dependencies are use to create tasks. Wide dependency triggers a shuffle operation and wide dependency act as a task execution boundary splitting the execution in to stages.
Pipelining
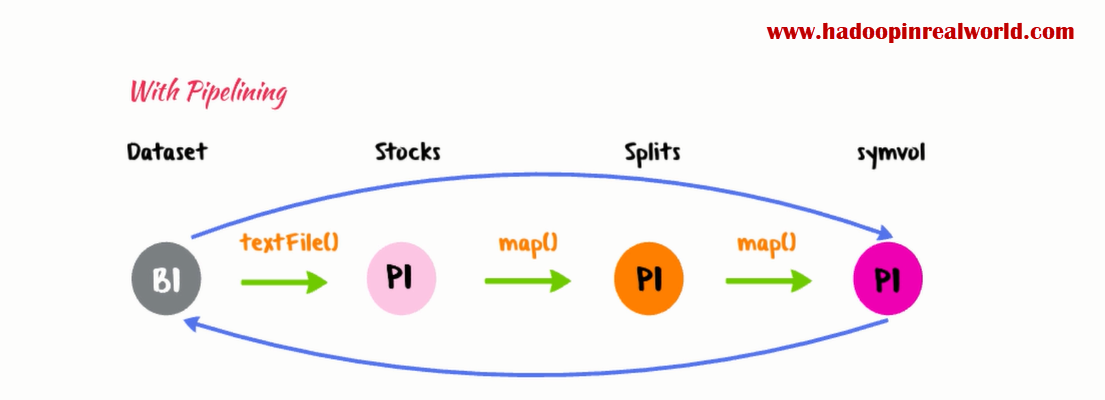
Inside a stage all the continuous narrow dependencies across partitions are grouped together as tasks. This concept of grouping all continuous narrow dependencies in to tasks is called pipelining. Pipelining is a powerful concept which is one of the main reasons behind the efficiencies in spark.
Let’s look at plan closer. It looks like task 1 reads block 1 creates partition 1 in stocks and then applies split function on partitions 1 in stocks to create partition 1 in splits and then extract symbol and volume from partition 1 in splits to form symvol. This is not what happens at runtime because this is inefficient. Because the task has to loop through the elements in the partition 3 times.

Instead with pipelining, task 1 takes record 1, split the record, extract symbol and volume back to back. You can see the execution is pipelined. With this execution style we have to loop through the elements in the partition only once. Now imagine we have 10 RDDs in narrow dependency and a partition has about a million elements. Pipelining execution will have a tremendous performance benefits.
Let’s now look at how Spark will plan the execution. This whole illustration in the picture below is a job that would be executed in a spark cluster, this job has 2 stages, stage 0 has 4 tasks and stage 1 has 4 tasks so this job has a total of 8 tasks. What we see here is the physical plan, which act as a blue print for execution.
Fault Tolerance
So now we know how our instructions gets translated in to jobs, stages and eventually tasks. We also now how dependencies play a role in creating stages and tasks. Now let’s see how dependencies affect fault tolerance.

Let’s say Spark is currently executing stage 0 and tasks 0 is assigned run on node 0, task 1 was assigned to run on node 1, task 2 on node 2. so on and so forth. Let’s now say in the middle of stage 0 execution, node 2 executing tasks 2 went down. how do we recover from this failure. Very simple, run task 2 on another healthy node. The fault we just experienced is local to task 2 and all we have to do is execute task 2 on another node and we are fine.
Let’s now say in the middle of stage 1 execution node 6 executing task 6 went down. Now how do we recover?
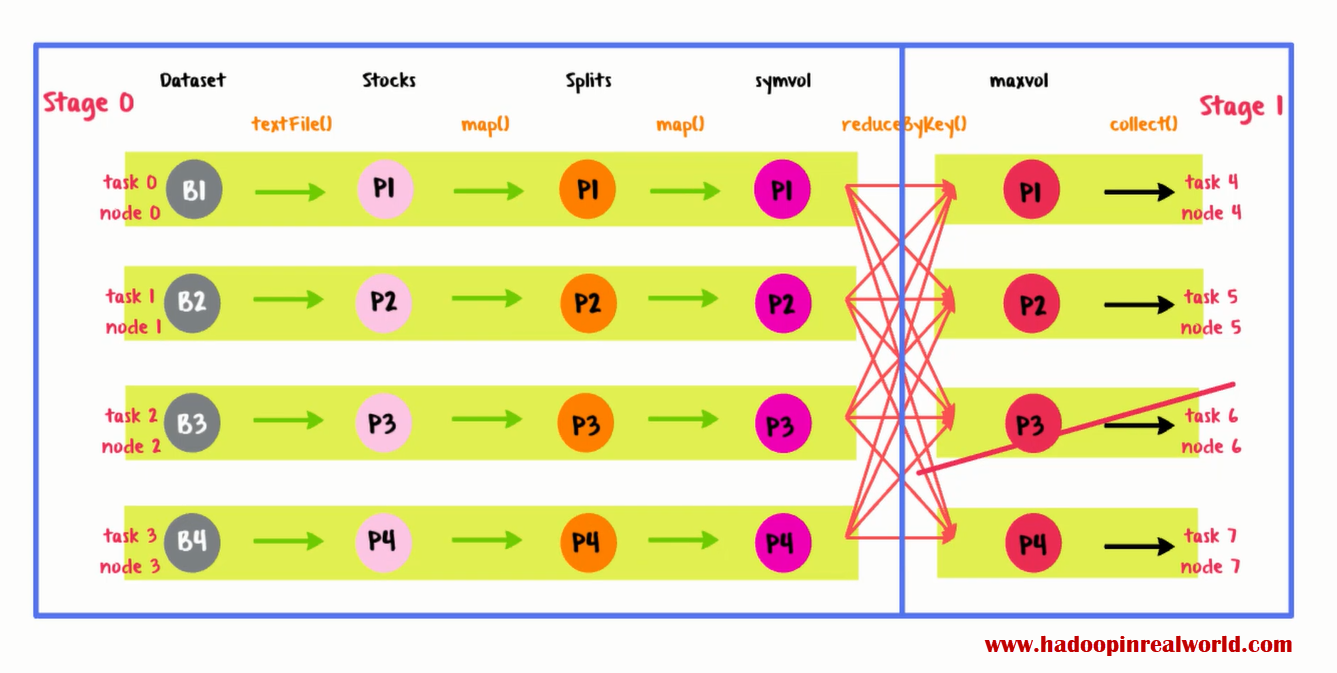
We certainly have to execute task 6 on another healthy node. But task 6 is right after a wide dependency it depends on the output from task 0 through 3 and this means we need node 0 though 3 available to recover from node 6 failure. If any of the nodes 0 through 3 are not available or the output of tasks 0 through 4 are not available then we need to re-execute those missing tasks on another node and proceed with the execution.
If you compare the recovery after node 2 failure and recovery after node 6 failure. Node 2 recovery is less painful compared to node 6 failure. So recovering tasks right after a wide dependency could be time consuming when the dependent tasks and it’s data are not available.
Alright, in this post we say how our code gets translated in to stages, tasks for execution. In short we now understand how a physical plan looks like and how it is created. Also we looked at how dependency plays a major roles in creating stages and tasks and also how dependency affect fault tolerance


No comments:
Post a Comment